
The Problem with How AI Reads Your Website
Your website was built for humans — and for Google.
Every design decision, every meta tag, every sitemap entry was made with one audience in mind: a search engine crawler that ranks pages by relevance, or a human visitor who reads and clicks.
But something shifted in the past 18 months. A new class of visitor has arrived at your site — and it doesn’t read HTML the way Googlebot does.
AI agents like ChatGPT, Perplexity, Claude, and Gemini don’t browse your homepage. They don’t follow your navigation menus. They can’t render your JavaScript-heavy product pages or make sense of your <div> stacks. When they arrive at your website, they’re looking for structured, parseable content they can extract, synthesize, and cite — fast.
Without clear signals about what matters on your site, they guess. And when AI systems guess, they often surface outdated blog posts, pull information out of context, or skip your site entirely in favour of one that’s easier to parse.
That’s the problem llms.txt was designed to solve.
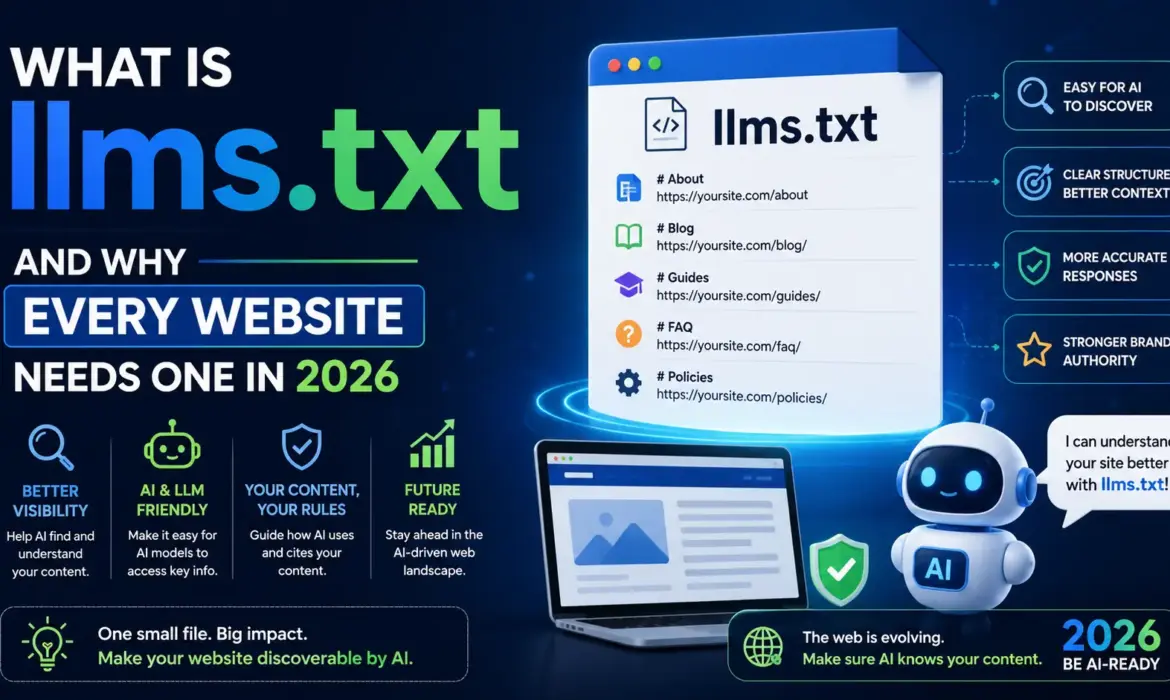
What Is llms.txt?
llms.txt is a plain-text, Markdown-formatted file placed in your website’s root directory that acts as a curated content guide for AI language models — telling them what your website is about, which pages matter most, and how your content should be understood.
Think of it as the AI-era equivalent of robots.txt — but instead of telling crawlers what not to access, llms.txt tells AI systems what to focus on.
The concept was proposed by Jeremy Howard of Answer.AI in September 2024, and it has since gained meaningful traction in the developer and SEO communities. The file lives at a predictable location (yourdomain.com/llms.txt) and uses clean Markdown syntax because Markdown is the “native language” of large language models — no complex parsing required.
A basic llms.txt file looks like this:
markdown
# Smacpage Technology
> A full-service digital marketing and web development agency helping
> businesses grow through SEO, GEO, and high-performance websites.
## Core Services
– [SEO & GEO Strategy](/services/seo-geo): Search and AI visibility services
– [Web Development](/services/web-development): Custom websites and CMS builds
– [Digital Marketing](/services/digital-marketing): PPC, social, email marketing
## Key Resources
– [GEO Complete Guide](/blog/what-is-geo): What GEO is and how to implement it
– [Core Web Vitals Guide](/blog/core-web-vitals-2026): Technical performance guide
– [Case Studies](/case-studies): Client results and project examples
## About
Founded in 2020. Based in Pittsburgh, USA. Specialising in B2B and local business growth.
That’s it. Simple, structured, and immediately useful for any AI system trying to understand what your business does and where to find your best content.
How AI Systems Actually Read Websites (And Why That Changes Everything)
To understand why llms.txt matters, you need to understand how AI-powered search engines operate differently from traditional crawlers.
Traditional search crawlers (Googlebot):
- Systematically crawl and index all accessible pages over time
- Build a persistent, searchable index of your content
- Retrieve from that stored index when users search
- Match queries to pages based on keywords, backlinks, and ranking signals
AI language models and agents:
- Often retrieve web content on demand, in real time, at query time
- Have limited context windows — they can only process a finite amount per request
- Struggle with JavaScript-rendered content, complex navigation, and heavy HTML
- Need to decide quickly which pages are worth processing
The critical difference is this: Googlebot has time and infrastructure to index everything. AI agents, operating under context window constraints, need to make fast decisions about where to focus. A page buried under three levels of JavaScript rendering, surrounded by navigation menus and cookie banners, may simply be skipped.
llms.txt solves this by providing a clean, pre-organised summary that points AI systems directly to high-value content — skipping the noise entirely.
As one guide puts it: “LLMs can parse HTML, but they waste tokens on your <div> soup. What if you could hand these models a single, clean page containing only the essentials?”
llms.txt vs. robots.txt vs. sitemap.xml: What’s the Difference?
These three files coexist in your root directory and serve distinct purposes. You need all three:
| File | Purpose | Audience | Controls |
| robots.txt | Controls crawler access | All bots | What crawlers can and can’t visit |
| sitemap.xml | Maps all indexable pages | Search engines | Full site discovery and prioritization |
| llms.txt | Curates priority content | AI language models | What AI should focus on and how to understand it |
robots.txt is a gate. sitemap.xml is a map. llms.txt is a guided tour of your best content.
They don’t conflict — they complement each other. robots.txt sets the boundaries, sitemap.xml ensures complete discovery, and llms.txt ensures that when AI agents arrive, they understand what you do and head directly to your most authoritative content.
Who’s Already Using llms.txt?
Adoption is growing fastest among developer-oriented and AI-native companies, where the practical benefits are most immediate:
Anthropic has published an llms.txt file on their own website, signalling openness to the standard from one of the world’s leading AI companies.
Vercel uses llms.txt to include contextual descriptions for agents deciding which API endpoints to fetch — meaning developers using AI coding tools to work with Vercel’s platform get more accurate answers because the AI model oriented itself correctly before fetching documentation.
Cursor and GitHub Copilot — AI coding assistants — actively retrieve llms.txt files to understand developer documentation in real time. For software companies and agencies with developer-facing content, this is where llms.txt delivers the most immediate, measurable value.
Maryland.gov became the first US state government website to implement llms.txt, signalling that the file is moving from developer experiment to institutional standard.
Yoast SEO (the WordPress plugin used by millions of websites) now generates llms.txt automatically — a strong signal that the standard is moving toward mainstream adoption. Rank Math offers a similar feature in their plugin ecosystem.
As of mid-2026, adoption sits at roughly 5–15% among tech and documentation-heavy websites. That means the window for first-mover advantage in your industry is still wide open.
What llms.txt Does — and What It Doesn’t
There’s been some confusion around llms.txt in the marketing community, so it’s important to be precise about both the genuine benefits and the current limitations.
What llms.txt genuinely does:
Points AI to your best content. When AI agents retrieve your site, the file acts as a curated shortlist — steering them toward your service pages, cornerstone guides, and case studies rather than a five-year-old blog post that ranks for a tangential keyword.
Reduces AI hallucinations about your brand. When an AI model attempts to describe what you do without a clear content reference, it relies on whatever it encountered during crawl — which might be outdated, third-party, or competitor content. llms.txt reduces this risk by giving AI a direct, accurate description of your business.
Delivers immediate value for developer tooling. AI coding assistants like Cursor and GitHub Copilot retrieve llms.txt files in real time. If your agency has developer documentation, API references, or technical guides, llms.txt improves the accuracy of AI-generated answers about your services right now.
Positions you for the agentic web. AI agents — systems like OpenAI’s Operator that browse and complete tasks on users’ behalf — are the next evolution of AI search. These agents need structured, machine-readable navigation to operate efficiently. llms.txt is the groundwork for that future.
What llms.txt does not (yet) do:
It does not improve your Google rankings. Google’s John Mueller confirmed in 2025 that no Google Search ranking system reads or acts on llms.txt. This file has no direct effect on traditional organic search performance.
It is not an enforced standard. As of mid-2026, no major AI company — including OpenAI, Google, Anthropic, or Meta — has publicly committed to reading or acting on llms.txt in their production systems. Server log analysis shows that AI crawlers (GPTBot, ClaudeBot, PerplexityBot) access the file occasionally, but this is not the same as confirmation that it influences how these systems source or cite content.
It cannot block AI crawlers. Unlike robots.txt, llms.txt is not a blocking mechanism. It is a navigation file. If you want to restrict AI access to specific content, that must be handled through robots.txt directives.
Duplicate content risk if misimplemented. A common mistake is creating individual Markdown copies of every page and making them all indexable. If those Markdown files are crawlable by Googlebot, they introduce duplicate content at scale, which can suppress rankings for your original pages. Keep Markdown files referenced in llms.txt either noindexed or served as separate, clearly distinct resources.
How to Create Your llms.txt File (Step by Step)
Step 1: Identify Your Priority Content
Start by selecting the 10–20 pages that best represent your business. These typically include:
- Your main service or product pages
- Cornerstone blog posts and guides (your most comprehensive, authoritative content)
- Case studies and results pages
- Your About page and team credentials
- FAQs and resource hubs
Leave out contact forms, thin pages, paginated archives, old or outdated posts, and any content you wouldn’t want an AI system to cite as representative of your brand.
Step 2: Write the File in Markdown
Open any plain text editor. Name the file llms.txt. The structure should follow this pattern:
markdown
# [Your Business Name]
> [1–3 sentence description of what your business does, who you serve,
> and what makes you the authoritative source on your key topics.]
## [Section Name — e.g., Services]
– [Page Title](/page-url): Brief description of what this page covers
– [Page Title](/page-url): Brief description
## [Section Name — e.g., Key Guides]
– [Guide Title](/blog/slug): What this guide covers and who it’s for
## Optional: Notes for AI Systems
This file covers public-facing content only. [Any guidance on how AI
should attribute or interpret your content.]
Keep descriptions specific and factual. The goal is not marketing language — it’s clear, machine-readable context. “Comprehensive guide to Core Web Vitals optimization including LCP, INP, and CLS benchmarks for 2026” is better than “Our amazing SEO blog.”
Step 3: Place the File at Your Root Directory
Upload llms.txt to yourdomain.com/llms.txt. It must be at the root — not in a subfolder. Verify it’s publicly accessible by visiting the URL in your browser. The file should load as readable Markdown text with a 200 OK status.
Step 4: Verify and Test
- Visit https://yourdomain.com/llms.txt in your browser to confirm it’s accessible
- Check that the response status is 200 OK (not redirecting or returning a 404)
- Ensure the Content-Type header shows text/plain
- Verify all linked URLs load correctly and aren’t blocked in robots.txt
- Monitor your server access logs for requests from AI user-agents (GPTBot, ClaudeBot, PerplexityBot, Google-Extended)
For WordPress users:
Enable llms.txt generation in Yoast SEO under SEO settings (one-click activation, no code required). Rank Math offers a similar plugin integration. Both auto-generate the file from your published content and update it as your site grows.
For other platforms:
Webflow provides a system to upload the file directly to your root. For custom-built sites, your developer can serve the file as a static asset or generate it dynamically from your CMS.
llms-full.txt: The Companion Format
You may also encounter references to llms-full.txt — the companion to llms.txt. While llms.txt is a navigation file (pointing AI to your best pages), llms-full.txt contains your complete site content in a single Markdown document for deep AI ingestion.
llms-full.txt is most valuable for:
- Developer documentation sites where AI tools need the full content of your docs in a single, parseable resource
- Technical agencies whose content is frequently used as context in AI coding workflows
- Companies with extensive knowledge bases used by AI-powered customer support tools
For most business websites, llms.txt alone is sufficient. Start there.
Where llms.txt Fits in Your GEO Strategy
llms.txt is one layer of a complete Generative Engine Optimization strategy — specifically the discovery layer: ensuring AI systems can find and understand your content.
A complete GEO stack includes five layers:
- Discovery — llms.txt, AI crawler access in robots.txt, technical crawlability
- Content structure — Direct-answer openings, named statistics, FAQ schema, heading hierarchy
- Technical signals — Schema markup, Core Web Vitals, fast load times, clean architecture
- Entity authority — Author credentials, LinkedIn presence, third-party citations on G2, Clutch, and industry directories
- Brand mentions — Expert placements in trade publications, forum participation, earned media
llms.txt addresses layer one. It ensures AI agents don’t waste their context window on your navigation menus and cookie banners. But it works best when the pages it points to are also optimised for AI citation — structured, data-rich, authored with clear expertise, and referenced across multiple authoritative third-party sources.
Should You Implement llms.txt Right Now?
The honest answer: yes — with appropriate expectations.
llms.txt is not a magic ranking lever. If you implement it tomorrow, you won’t see an immediate spike in AI citation frequency or organic traffic. No major AI platform has officially committed to prioritising it in their production systems as of mid-2026.
But here’s why it’s still worth doing now:
Implementation cost is low. For most websites, creating and uploading a well-structured llms.txt file is a one-to-two-hour task. WordPress sites with Yoast can do it in minutes. The effort-to-upside ratio is highly favourable.
The trajectory is clear. Adoption among developer-forward companies is already at 5–15% and growing. CMS platforms are adding native support. Government sites are implementing it. When this becomes a de facto standard — and the trajectory strongly suggests it will — early adopters will already have established AI content signals.
It reduces AI hallucinations today. Regardless of citation tracking, having a clear, accurate description of your business in a machine-readable format reduces the risk of AI systems misrepresenting what you do. That matters every time a prospective client asks an AI about agencies in your space.
It future-proofs you for agentic search. AI agents that browse the web and complete tasks on users’ behalf are the next phase of search evolution. These systems depend on structured navigation files to operate efficiently. Building that infrastructure now means you’re ready when the shift accelerates.
The competitive window is open. Most of your competitors haven’t done this. In most industries, the majority of websites have no llms.txt at all. First movers in AI content architecture historically build compounding advantages.
Action Checklist
Here’s everything your team needs to implement llms.txt correctly:
- Audit your site to identify the 10–20 most important pages
- Write a 1–3 sentence accurate description of your business for the file header
- Create llms.txt using Markdown formatting
- Place the file at yourdomain.com/llms.txt
- Verify the file returns 200 OK and is publicly accessible
- Check all linked URLs are live and not blocked in robots.txt
- Ensure any Markdown companion pages are noindex to prevent duplicate content
- Set a calendar reminder to update the file quarterly as your content evolves
- Monitor server logs for AI crawler access (GPTBot, ClaudeBot, PerplexityBot, Google-Extended)
- Cross-reference with your robots.txt to ensure AI crawlers can access your priority pages
Final Word
The web has always rewarded the businesses that adapted early to structural changes in how information is discovered. In 1998, that meant getting indexed by Google. In 2012, it meant earning backlinks. In 2019, it meant structured data and featured snippets.
In 2026, it means building a website that AI systems can understand, navigate, and cite with confidence.
llms.txt is not the whole answer — but it is a low-cost, high-leverage first step. It costs your team a couple of hours. It positions your brand accurately in the AI systems your prospects are already using. And it builds the infrastructure that the agentic web will depend on.
There’s no good reason to wait.
Need help implementing llms.txt and building a complete GEO strategy for your website? Our web development and digital marketing team can audit your current AI visibility, implement the full technical stack, and create the content architecture that gets your brand cited. Talk to us →
